
Let a thousand benchmarks bloom that are EASY for humans but HARD for AI
The framework of grid-worlds is even more robust for testing capabilities in the human-machine intelligence gap than perhaps the ARC team realizes.

The ARC challenge is in a league of its own by creating tasks that are EASY for humans but HARD for AI. It’s a framework that’s already shown to have enduring legs, but it has even more potential than I think the ARC team realizes. That’s what I’m going to briefly talk about below.
What is ARC? Version 1.
Here’s how an ARC task works. You’re given some number of examples of input-output grids that illustrate some implicit underlying task. Then there’s the test: from an input grid given to you, make the output grid that completes the task. For example, in the left half of the image below there are two input-output examples. Then in the right half there’s the test: an input that’s given to you, and a blank output grid that you need to edit.
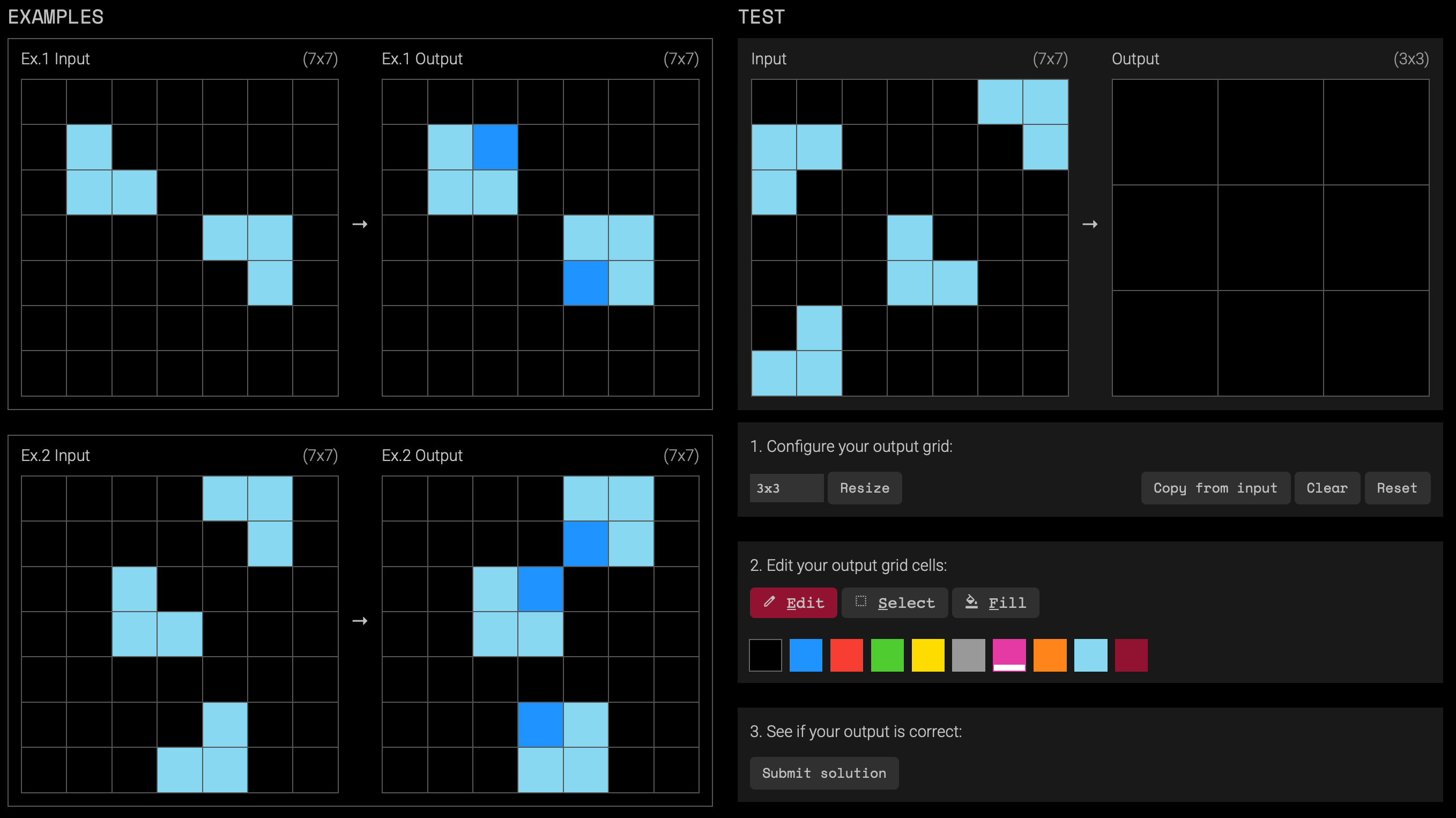
One way to describe the implicit task in this example is, “using a darker blue pixel, fill in the missing corner of squares.” By editing the output grid in the test, the completion of the task would look like this:
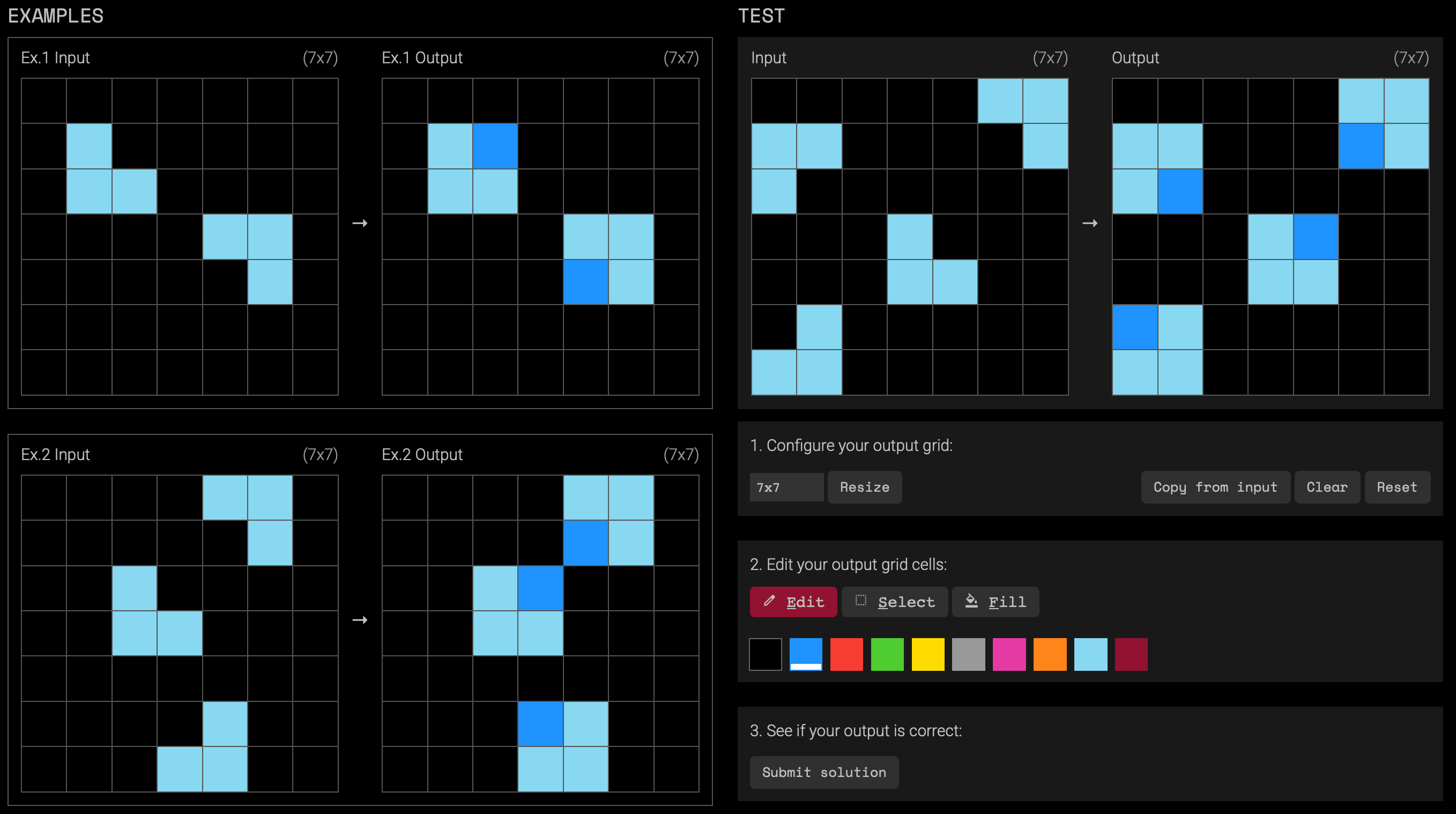
There are hundreds of tasks like this with varying degrees of complexity. When you’re done reading, try out some for yourself: https://arcprize.org
Version 2 of ARC
The first version of the challenge, simply called ARC-AGI, was unbeaten for five years (2019-2024). Actually, strictly speaking, it wasn’t beaten if you account for the fact that the only model that passed it (OpenAI’s o3) failed to be efficient. By the most conservative estimates, o3 required thousands and thousands of dollars in electricity (less conservative estimates are in the hundreds of thousands). Meanwhile, a human needs at most a few minutes to solve ARC tasks, equivalent to less than the cost of a grain of rice to power a brain.
The five year reign of ARC-AGI is in stark contrast to just about every other benchmark. Nearly every standardized test can now be aced by large language models (LLMs). And newer benchmarks that try to measure PhD+ level skills or even super-intelligence don’t tend to last long before they’re beaten.
Yet, those same cutting-edge frontier models of intelligence can’t solve a task that just about every adult human can do within a few minutes. Clearly, there is a massive gap between human and machine intelligence, despite all the hype.1
What we don’t yet fully understand are the various capabilities that make up that gap. Towards better understanding those capabilities, this week we saw the release of the second version: ARC-AGI-2. Here’s a screenshot of a task in the updated corpus. It might take a bit longer to see the pattern in comparison to the above example, but it’s still easy to solve if you’re willing to put in a bit of thought:
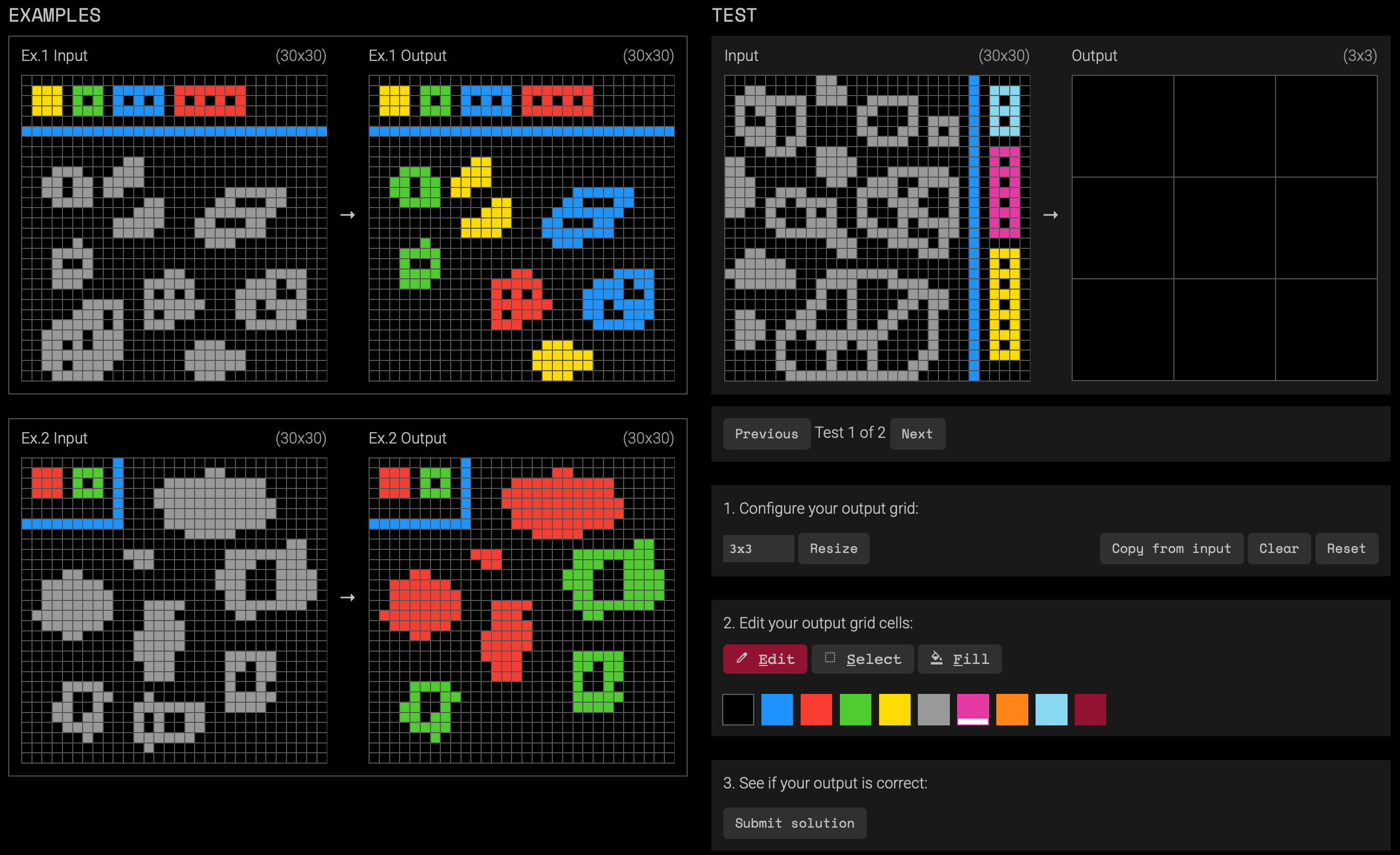
The implicit task instruction is something like this: using the colored blocks in the input grid as a key, color the gray blobs according to the number of holes they have, and remove the blobs with numbers of holes not represented in the key. So the solution looks like this:
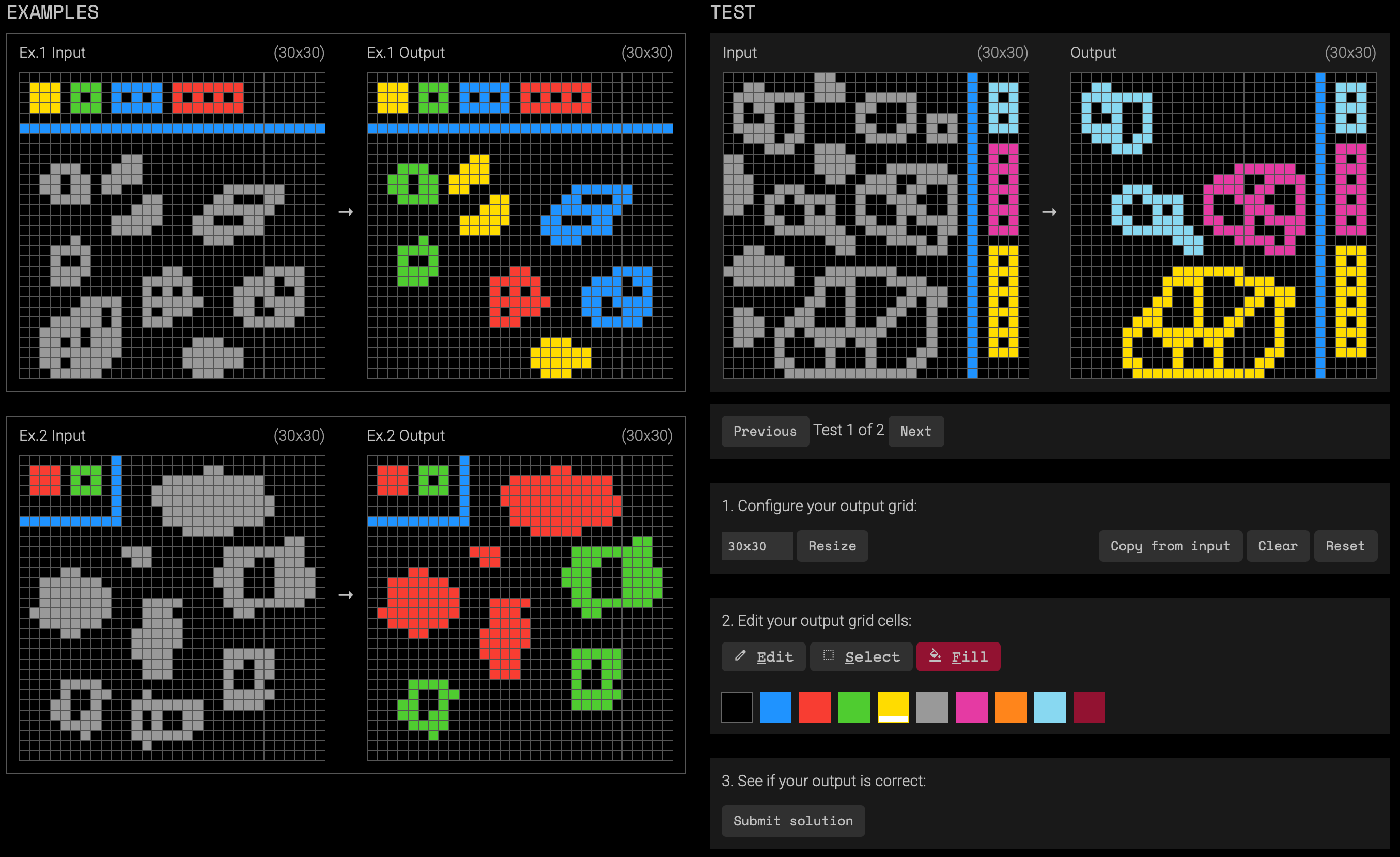
ARC2 is designed to explore at least three kinds of capabilities that humans have: symbolic interpretation (like the coloring key example above), compositional reasoning, and contextual rule application. These kinds of capabilities have long been touted by philosophers, linguists, and cognitive scientists as central to human intelligence. And sure enough, frontier AI models are scoring basically zero on ARG-AGI-2.
ARC is a fruitful framework for studying other capacities, for metaphor reasoning and taking agency perspectives
Compositionality and the like are not the only capabilities in the current gap between human and machine intelligence, which the ARC team recognizes in the launch video for ARC-AGI-2. In fact, they’re already working on the third version. No, this isn’t a case of preparing to move the goal post (I’ve written about why not in more detail here). Rather, these kinds of “benchmarks” are ways of studying the various capabilities that make up our current understanding of the human-machine intelligence gap. That gap is likely filled with a diverse range of capabilities, and so we should expect a diverse range of benchmarks accordingly.
To that end, the grid worlds that make up ARC tasks provide a robust framework for exploring a range of capabilities. I’ve written about my own plan for using it to test capabilities for thinking in metaphor and for attributing agency to predict behavior. Here I want to share a recent example from my team.
The key idea in our version is that ARC-style puzzles are supplemented with a description that can be used as a clue. Importantly, the description is not literal, like the way I described the implicit tasks above. Rather, the description is applied to the grid-world through a capacity for metaphor. Without the description, the solution to the puzzle would be much more difficult, if not impossible. Let me illustrate.
Have a look at this puzzle:
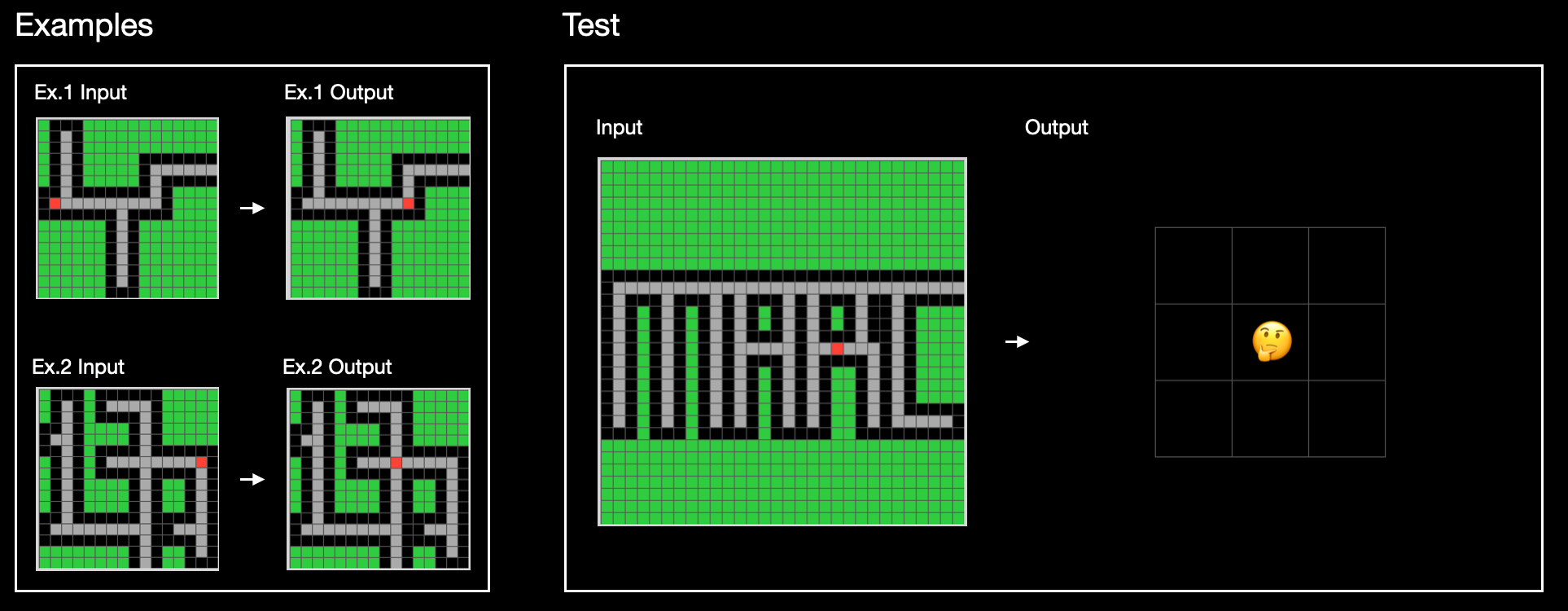
In the examples, you’ll notice that the red dot moves along the gray lines. Once you notice that, you’ll probably think about what the implicit task is that explains why the red dot moves in the pattern that it does. If you can figure that out, then you’ll be able to predict the output in the test.
When I’ve shown this puzzle to people, the majority of them venture one of two guesses of where the red dot will go:

But both are wrong, according to the intended task.
With a simple description, however, people grasp the intended task almost immediately. Ready?
“One step closer to freedom.”
What counts as freedom in this puzzle? If you have a capacity for metaphor, you’ll notice that the gray “road” has an “escape” at the top right of the letter C that is spelled out in the grid.
What counts as being one step closer? It’s not moving one pixel at a time. It’s also not moving along a path until an object is blocked. Rather, moving one step is about moving along a line until you have to change direction.
And one thing you probably hardly notice doing: you can attribute agency to the red dot. The red dot wants to escape, intends to act on a plan that has steps, and the output is the first step in that plan:
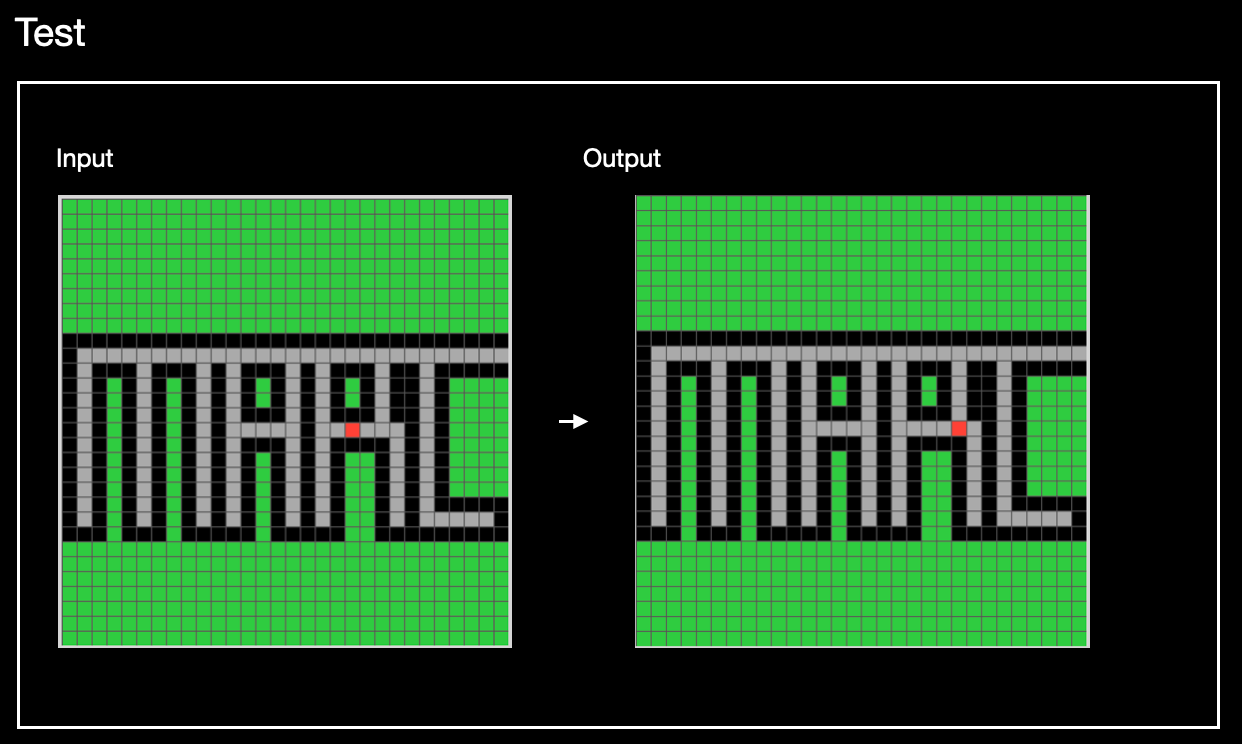
My prediction is that current frontier models will struggle to complete these kinds of “metaphor + ARC” tasks (aka MARC tasks). This is because, like the capacity for compositional reasoning, the capacity for metaphorical reasoning is not accounted for by the capacity of next-token prediction that undergirds current LLMs and the more recent large reasoning models (LRMs). There’s also related evidence about how LLMs and LRMs struggle with analogies.2 But before my prediction can be properly tested, we need to build a sufficiently large corpus of MARC tasks. (As of this writing, I’m only at about two dozen or so.)
Here another opportunity emerges. MARC tasks can be created by people with no technical skills. In creating MARC tasks, you do have to keep in mind that it should be easy for humans but hard for AI. What makes something hard for AI requires you to have some rough idea about the kinds of tasks that they struggle with. Developing that kind of understanding does NOT require you to take formal courses in things like machine learning. What it does require is that you have developed some familiarity with using tools like ChatGPT or Gemini, where you get a sense of the sorts of things that chatbots are good at and the things they aren’t.
In other words, all that making MARC tasks requires is a bit of AI literacy from a task-oriented perspective.
That, incidentally, is my strategy for growing AI literacy. By starting with existing puzzles from ARC and getting people to create new puzzles for MARC, we can establish a common ground to discuss and demonstrate the awesomeness of human creativity, and thereby better understand the gap between human and machine intelligence.
If you’re interested in joining my team, please reach out to me by email (bbaum@uidaho.edu) and include “MARC” in the subject line. Also reach out to me if you’re interested in helping me run a campus-wide competition to create novel MARC tasks (Fall 2025). And especially reach out to me if you’d be willing to sponsor prizes!
May thousands of benchmarks bloom.
To be clear, the hype about how awesome LLMs are as tools is warranted. It’s the hype about reaching human-level intelligence that I’m suggesting we should be extremely skeptical of.